This is a tutorial to show the basic API usage of fanout queue, the source of this tutorial is here.
Why we need a queue with fanout semantics? here is a typical case: Suppose we have a queue for log collecting, at the backend, we have two(or more) use cases of the log data, for example, one use case is real-time log analysis and alerting, another use case is offline log analysis and reporting, in these cases, we will have two(or more) independent consumers, such as one real-time log consumer and one offline log consumer, but we only have one queue, if we just use a typical queue, then it only supports one consumer(this is called consume once queue), the data consumed by one consumer will not be available to other consumer(s) again. One solution to this problem is to create two(or more) queues for each consumer, and let producers produce messages into all these queues, but this is a silly and bandwidth/storage cost solution. A more elegant solution is to add fanout semantics to the queue - one queue can be independently consumed by multiple consumers, internally, fanout queue will maintain queue front pointers for each consumer. The fanout queue in the bigqueue library supports fanout semantics, it also supports a group consuming scenario - multiple consumers form a group(use same fanout id) to consume a queue concurrently for higher consuming throughput.
Below is figure visually show the fanout semantics:
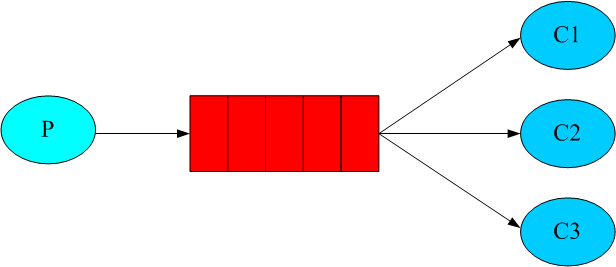
The interface of fanout queue is here.
You can create(initialize) a new fanout queue in just one statement:
1 2 | |
the first parameter is a directory you want to store the queue data file, the second parameter is the queue name. Now you have a reference to an empty queue.
At producing side, fanout queue is the same as typical queue, to add or produce item into the queue, you just call the enqueue method on the queue reference, here we enqueue 10 logs into the queue:
1 2 3 4 5 | |
Note: the enqueue method only accept byte array data as input, if your object is not byte array data, you are responsible to convert your object into byte array first before enqueue, this is called serialization, when you dequeue later, you are also response to de-serialize the byte array data into your object format.
Now let’s see the fanout semantics, to consume from a fanout queue, you need to provide a fanout id to uniquely identify the fanout queue, then call the dequeue method with fanout id as parameter, below we use a fanout id called ‘realtime’ to consume all logs in the ‘realtime’ fanout queue(‘realtime’ is just a logic name, there is only one physical underlying queue):
1 2 3 4 5 6 7 | |
below is the output:
1 2 3 4 5 6 7 8 9 10 11 | |
Now let’s suppose there is another consumer called ‘offline’, to consume all logs in the ‘offline’ fanout queue, we just use similar consuming logic:
1 2 3 4 5 6 7 | |
The only difference is now we use ‘offline’ as fanout id instead of ‘realtime’, below is the output:
1 2 3 4 5 6 7 8 9 10 11 | |
By comparing the output, you can see that both ‘realtime’ consumer and ‘offline’ consumer can consume one queue independently.
Finally, when you finish with the queue, just call close method to release resource used by the queue, this is not mandatory, just a best practice, call close will release part of used memory immediately. Usually, you initialize big queue in a try block and close it in the finally block, here is the usage paradigm:
1 2 3 4 5 6 7 8 9 | |
By the way, in current implementation, the fantout queue provided by bigqueue library does not limit the number of fanout queues, in other word, one queue can support arbitrary fanout consumers, as long as all consumer are using their respective fanout ids.
Fanout is a very powerful queue sementics, in a last project, we successfully used one log queue to support 3 kinds of log consumers:
- realtime consumer, filter and store log events in in-memory db for real-time event alerting.
- near-realtime consumer, store logs in HBase for daily log search and analysis.
- offline consumer, store logs in Hadoop for long term analysis and reporting.
Advanced Usage
Sometimes, one consumer is not enough to keep up the speed of the producers, in such case, we can let multiple consumers(may host on same machines or multiple machines) to form a consumer group, in such case, every consumer in the same group will use same fanout id, and every message in the queue will be consumed by one and only one consumer in the group. This is just the consume once semantics.
If different consumers or consumer groups use different fanout id to consume messages in same queue, then every consumer(or consumer group) can consume independently, means every message in the queue will go to every consumer(or consumer group). This is just the fanout queue semantics.
Fanout queue is backed by the big array structure, so it is also big, fast and persistent, the capacity of fanout queue is only limited by available disk storage, fanout queue also provides methods to clean up expired back data files or to limit the total size of the back data files, please see the interface and unit tests for details.
Note, the fanout queue interface also exposes the raw index based queue access interface to user, which means it’s possible to consume the queue by index, the interface is provided in case some user may need more flexible queue semantics, for example, to support transactional queue consuming by committing and saving index in DB or other persistent storage. It’s even possible to consume the queue randomly by index, although there may have performance issue in such case.