Overview
With the advent of big data era, we are facing more and more challenges from big data collecting and analytics requirements. Typical big data or activity stream includes but not limited to:
- Logs generated by frontend applications or backend services
- User behavior data
- Application or system performance trace
- Business, application or system metrics data.
- Events that need immediate action.
The Luxun messaging system is just tailored for big data collecting and analytics scenario, following are the main design objectives of Luxun messaging system:
- Fast and High-Throughput : This is the top priority feature, without this capability, the system will be easily overwhelmed by flooding data continuously generated by hundreds or thousands of machines, it is expected that both enqueue and dequeue speed should be close to O(1) memory access, and that even with modest hardware Luxun can support hundreds of thousands of messages per second.
- Persistent and Durable : Real business value can be derived from big data, so any data lose should be avoided as far as possible. Also, nowadays backend system maintenance(or even crash) is common, Luxun should persist messages on disk longer than the maintenance(or system recovery) window, to let backend systems continue to consume messages when they are up again. Regarding durability, Luxun should ensure the persistence of the message even the service process crashes.
- Separation of Producers and Consumers : Luxun should separate messaging producers and consumers using pub-sub style exchange pattern, each one can work without knowing the existence of the others, such kind of loosely coupled architecture can make the whole system robust, horizontal scalable, and easy to maintain.
- Realtime : Messages produced by producer threads should be immediately visible to consumer threads, this feature is critical to event based system like Complex Event Processing(CEP) system.
- Distributed : Luxun should explicitly support partitioning messages over Luxun servers and distributing consumption over a cluster of consumer machines while maintaining per-partition ordering semantics.
- Multiple Client Support : Luxun system should support easy integration of clients from different kinds of platforms(such as Java, .Net, PHP, Ruby, Python, etc), it’s desirable that producers and consumers can be auto-generated from Luxun service interface, by leveraging technology like Thrift RPC.
- Flexible consuming semantics : Luxun should support typical consume once queue, fanout queue, and provides more flexible consuming mechanism like consuming by index.
- Light Weight : The footprint of Luxun binary should be light, and the interface exposed should be simple and be understandable by normal user. Zookeeper like distributed coordination should be avoided since many small or medium scale companies still can’t afford it, and the learning curve of zookeeker to average developers is still steep.
Luxun makes a unified big data platform(or pipeline) possible, as illustrated in the figure below:

The figure shows a typical big data collecting and analytics scenario supported by Luxun messaging system:
At the producing side, there are different kinds of producers, such as:
- Frontend web applications producing application logs.
- External tracking proxies producing web analytics logs.
- Backend services producing service invocation trace logs.
At the consuming side, there are different kinds of consumers, such as:
- Offline consumers consuming messages and storing them in Hadoop or traditional Data Warehouse for offline analysis.
- Near realtime consumers consuming messages and store them in HBase or Cassandra for near realtime analytics.
- Realtime consumers filter messages in in-memory DB and trigger alert events to related groups.
Basic Concepts:
- Topic : Logically it’s a named place to send messages to or to consume messages from, physically it’s a persistent queue.
- Broker : Aka Luxun server.
- Message : Datum to produce or consume
- Producer : A role which will send messages to topics.
- Consumer : A role which will consume messages from topics.
- Consumer Group : A group of consumers that will receive only one copy of a message from a topic(or more).
Overall Architecture

Luxun has a simple architecture, the main components of a broker are:
- Persistent Queue : Physical implementation of logic topic, internally use memory mapped file, automatic paging and swapping algorithm, sliding window, index based access for fast queue operation while use memory in an efficient way.
- Thrift based Interface : Simple RPC based API exposing queue service to external clients.
- Producer Client : Wrapper around Luxun producing API, provides simplified interface for developers, also provides advanced partitioning, batching, compression and asynchronous producing features.
- Consumer Client : Wrapper around Luxun consuming API, provides simplified and stream style consuming interface for developers, supporting advanced distributed consuming, multi-threads concurrent consuming, group consuming features.
- Management and Monitoring: Server management and JMX based monitoring interface.
The Core Principle
The core principle of a fast while persistent queue system like Luxun is from a key observation that sequential disk read can be comparable to or even faster than random memory read, see a comparison figure below:

So if we can effectively organize the disk access pattern, then we can get fast performance comparable to memory which still have persistence. Queue is a rear append(or append only) and front read data structure, a nature fit to be implemented in sequential disk access mode.
The Design of the Persistent Queue
Logical View
The logic view of the persistent queue is fairly simple and intuitive, it’s just like a big array, see figure below:

you can access the queue using array like index, one special thing is that the index is of type long(in typical programming language, array index is of type int), so the queue can accomodate huge amount of data, only limited by available disk space. You may also think of the queue as a circular queue as shown in figure above, since the queue will wrap around when the long.max index is reached(although in practice, we don’t think current application will get chance to reach the long.max index:)).
With simple array like abstraction, we can implement queue semantics with ease:
- For a typical consume once queue, we just need one rear pointer pointing to the queue rear index, aka the next to be appended index, another pointer pointing to the queue front index, aka the next to be consumed index. When an item is produced into the queue, we add the data in the queue then advance the rear index, when an item is consumed from the queue, we fetch the data in the queue then advance the front index. In this case, multi-threads can concurrently produce into the queue, the queue internally will sync the append operation, and multi-threads can concurrently consume(by contention) the queue, and every item will only be consumed by one thread once. see figure below.
- For a fanout queue, we also just need one rear pointer pointing to the queue rear index, aka the next to be appended index, but on the consuming side, we let the queue maintain one queue front index for every fanout group, in other word, the fanout semantics is implemented in Luxun by letting Luxun server to maintain consuming state for every fanout group. In such case, multi-threads can concurrently and independently consume the queue, and every item will be consumed multiple times by different consumers as long as they belong to different consumer group(or fanout group). see figure below.

By the way, consume once queue is just a special case of fanout queue, so it’s not necessary for luxun to provide a separate consume one queue, as long as fanout queue has been provided.
In summary, Luxun queue is an append only queue, means at producing side, item can only be appended into the queue, while at the consuming side, flexible queue consuming semantics are provided by array like index access model and state maintained on server side.
Note, the Luxun queue service even expose the index based queue access interface to user, in case some user may need more flexible queue semantics, for example, to support transactional queue semantics by committing and saving index in DB or Zookeeper. It’s even possible to consume the queue randomly by index, although there may have performance issue in such case.
Physical View
Luxun queue is built on a big array abstraction, physically, one big array is implemented by:
- One Index file : store fix sized index item, aka pointer to data item in Data File.
- One Data file : store actual data item with variable length.
Index file and data file may grow very big, map whole index file or data file into memory may lead to unpredictable memory issue, so both Index file and Data file are further paged into fix sized sub-page files(in current setting, index page is 32M which can index 1M items, data page is 128M), and every sub-page has a corresponding index, at runtime, these sub-page files will be mapped into memory on demand.
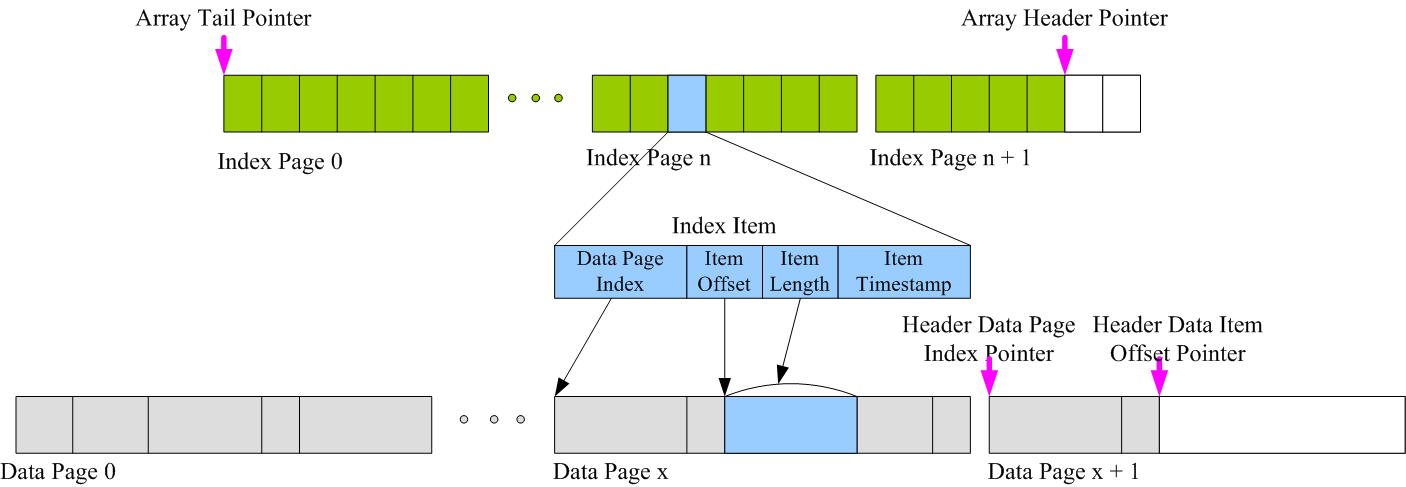
A fix sized Index Item consists of :
- 4 bytes
Data Page Index- pointing to the data page index where the target data item resides.- 2 bytes
Item Offset- data item offset within the data page file.- 2 bytes
Item Length- the length of the data item.- 4 bytes
Item Timestamp- the timestamp when the data item is appended into the big array.
Besides structures above, every big array has :
- An Array Header Index Pointer : pointing to the next to be appended array index.
- An Array Tail Index Pointer : pointing to the first array index(usually it’s 0 if we haven’t truncated the array)
- A Header Data Page Index Pointer : pointing to the next to be appended data page index.
- A Header Data Item Offset Pointer : pointing to the next to be appended data item offset within a data page.
Pointers 1 & 2 are persisted in memory mapped file, while pointers 3 & 4 are not persisted since they can be derived from pointers 1 & 2.
With data and file structures defined above, let’s see the simplified data item indexing and appending(producing) flow(we will use number listed above as abbreviated representation of pointer):
- Find the header data page file through pointer 3.
- Append the data into the data page file, starting offset from pointer 4, then update pointer 4 by adding the data length.
- Find the header index item through pointer 1.
- Update
Data Page Index,Item Offset,Item LengthandItem Timestampwithin the index item.- Advance pointer 1 by plus one(this also has transactional commit effect).
The simplified reading(or consuming) by index flow is even simpler:
- find the index item by the given index
- find the data item by inspecting
Data Page Index,Item Offsetin the index item- read the data item and then return it.
Algorithm to find index item given an array index:
1 2 | |
The divide, mod and multiply operations are further optimized by fast shifting operations.
Concurrency Consideration
In the design above, the append operation must be synchronized in concurrent case, while read operation is thread safe, the Array Header Index Pointer is just like a read/writer barrier, one and only one append thread will push the barrier, while multiple threads can concurrently read items behind the barrier.
Components View

Luxun persistent queue consists of following components:
- At the top is the Fanout Queue abstraction layer, Luxun interacts with this layer directly for queue operations like enqueue and dequeue.
- Fanout Queue is built on the Append Only Big Array structure, just as we explained in the logical and physical view above.
- The Append Only Big Array structure is built on Mapped Page Factory which are responsible for mapped page management, like page creation, on-demand load, caching, swapping, etc.
- At the lowest level are the Mapped Page which is the object model of memory mapped file, and the LRU Cache which are responsible for the page cache and swapping, for efficient memory usage.
Dynamic View
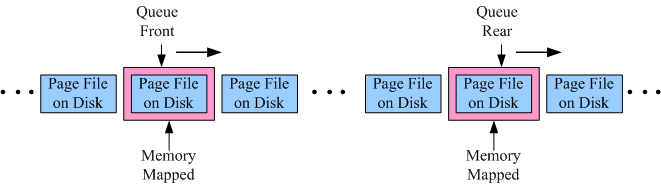
At runtime, Luxun queue looks just like a memory mapped sliding window:
- As new items are appended into the queue, the queue rear index will slide gradually towards the right, and the current appended page will be mapped and kept in memory.
- As items are read from the queue, the queue front index will slide gradually towards the right, and the current read page will be mapped and kept in memory.
Only the current active page files are mapped into memory, and they will be unloaded from memory if they are inactive in a specified time window, then new active page(s) will be loaded into memory as needed. The access pattern of queue((rear append and front read)) has very good locality, as long as we keep the current working set in memory, we’ll obtain both fast read/write performance and persistence, while at the same time the memory usage is efficient.
Other Design Consideration
The Queue Interface
The persistent queue exposes following interfaces for queue operations, monitoring and maintenance:
- enqueue(byte[] item) : append(or produce) binary data into the queue.
- byte[] dequeue : read(or consume) binary data from the queue.
- isEmpty : check if the queue is empty.
- getSize : total number of items remaining in the queue
- removeBefore(long timestamp) : remove index and data pages before a given timestamp, this may delete back files and advance the queue front pointer accordingly. This interface is useful to remove expired data files, to clean up already consumed data or to avoid too much disk space being used up. Luxun supports a
log.retention.hourssetting, internally, Luxun will periodically check data files outside the retention window, and remove them using theremoveBeforeinterface.- limitBackFileSize(long sizeLimit) : limit the total size of back index and data page files, this may delete back files and advance the queue front pointer accordingly. This interface is useful to limit the total size of back files, to clean up already consumed data or to avoid too much disk space being used up. Luxun supports a
log.retention.sizesetting, internally, Luxun will periodically check the total size of back files and uselimitBackFileSizeinterface to prune some old back files to maintain size.- getBackFileSize : Get current total size of back files of a queue.
- findClosestIndex(long timestamp) : find index closest to a given timestamp, this interface is useful in some cases that user want to consume by index and from a specific timestamp.
- flush : force to persist newly appended data, usually, this interface is not needed since OS will be responsible for the persistence of memory mapped buffer. We leave this interface to user in case they may need transactional reliability and they are aware of the cost to performance.
Note, in our queue design, enqueue only accept binary data as input, and dequeue only returns binary data, serialization and deserialization are outside the consideration of big queue design, in other word, Luxun can only see plain and raw bytes, we choose this design because:
- This can simplify the queue design and implementation.
- There are already a couple of mature and high performance serialization frameworks out there, such as protobuf, thrift, avro, just name a few, We can’t do better than these already established frameworks.
- We give the flexibility to user to choose their preferred serialization framework.
Reusability
The big array structure(aka the persistent queue) is implemented as a standalone library, since its usage it not limited to Luxun only, any applications that need a fast, big and persistent queue can reuse the big array library, the source of this library is here.
The Design of Thrift based Communication Layer
Rationality
We choosed Thrift to implement the communication layer of Luxun, because:
- Thrift is stable and mature, it was created by Facebook, now it’s an Apache project, it has been successfully used by famous projects like Cassandra and HBase.
- Thrift has high performance, it provides highly effective serialization protocols like
TBinaryProtocoland server model likeTNonBlockingServer(so you won’t get troubled with building your own NIO server which is very tricky and error prone). High performance binary RPC support and non blocking server model are main attractive features that lead us to choose Thrift, since Fast Wire Serialization, High Throughput, Highly Concurrent and NonBlocking Communication are top priority architecture and design objectives of Luxun.- Thrift is simple and light-weight, you just need to define a simple interface using its light-weight IDL(interface definition language), then you can auto-generate basic server and client proxy code without much effort, this can not only minimize development effort, but later upgrading effort - you just need to update the IDL then re-generate.
- Thrift has good cross-language support, supported platforms include but not limited to Java, CSharp, C++, PHP, Ruby, Python. One big factor we choose Thrift is - after we build the Thrift based Luxun queue service, clients for different language platforms are basically ready, If We need a client for languge X, We can easily generate one using its universal code generator.
- Thrift is flexible, Thrift has a pluggable architecture, transport protocols(like tcp or http), serialization protocol(like TBinaryProtocol, TJSONProtocol) and server models(like TNonBlockingServer, TThreadPoolServer) are all changeable according to your real needs.
Basically, We think guys at Facebook have made a really cool RPC framework, greatly simplified service development.
Components View
Programming with Thrift just like playing with building blocks, see components view of the Luxun client and server below:

- At the lowest layer is the underlying IO supported by Java language platform.
- In the middle layer are components provided by Thrift, in Luxun implementation, on server side, we chosen:
TnonblockingServerSocketasTTransportprotocol;TBinaryProtocolasTProtocolserialization protocol;- and
TNonblockingServeras server model.
on client side, we chosen:TSocketasTTransportprotocol;TBinaryProtocolasTProtocolserialization protocol.- The
QueueService.ProcessorandQueueService.Clientare proxy auto-generated from Luxun service IDL, will be elaborated on later.- On top layer are the Luxun implementation of the queue service interface, on server side, we implement
QueueService.Ifacein a class calledLogManager, which will communicate with clients through the generatedQueueService.Processorproxy and delegate the real queue operations to the underlying persistent queue; On client side, we implement producer or consumer specific code, which communicates with the server through the generatedQueueService.Clientproxy.
Luxun Thrift IDL
The Luxun Thrift IDL is the messaging contract between Luxun server and clients(producers or consumers), see its formal definition below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | |
This is a quite simple and intuitive interface, let’s elaborate on supported calls one by one:
- The produce call append binary data into the queue, you need to provide the target topic and the binary data as input, the response will return the operation result and the appended index if the operation is successful. The is a confirmed produce call, suitable for use case when strong transactional confirmation is needed.
- The asyncProduce is similar in functionality to the produce call, the difference is that asyncProduce is an one way call, this call does not block to wait for the response, it just fires the request then forgets, hence it will have better performance, our tests show asychProduce is 3 times faster than produce, this interface is used in Luxun high-level producer implementation for better producing performance.
- The consume call supports to kinds of operation modes,
- consume by fanout id: this is just the fanout queue semantics support, in such mode, you need to provide target topic, a fanout id and a max fetch size as input, the response will return a list of binary data if the operation is successful.
- consume by index: this is a more flexible queue semantics support, in such mode, you need to provide target topic, a start index and a max fetch size as input, the response will return a list of binary data if the operation is successful.
Note, if both fanout id and start index are provided, then fanout id will take precedence. The max fetch size parameter is required to support batch consuming - one consume operation can fetch data up to the max fetch size, then return the whole batch list of binary data, this can improve consuming throughput a lot. If you just need to consume one item at a time, set max fetch size to <= 0;- The findClosestIndexByTime call is useful if you want consume by index semantics and want to find an index by a specific timestamp. You need to provide a target topic and a timestamp as input, the response will return closest index if the find operation is successful.
- The deleteTopic call is used for deleting any unused topics, you need to provide a target topic and a authentication password(set on server side) as input, the response will return operation result, this is a call for queue administration.
- The getSize call just returns the total number of items remaining in a topic, this is a call for queue status query, if fanout id is provided, then the size of specific fanout queue will be returned, if no fanout id is provided, then the size of underlying queue(big array) will be returned.
Simplicity is the ultimate design objective of the Luxun queue IDL, in order to simplify clients implementation and to make the interface understandable by average developer, at the time, future extension is easy because of the flexibility and IDL driven development provided by Thrift.
The Design of the Producer
The raw producer client generated from Luxun queue IDL can be used directly in real application, however, we believe the raw client is too low level for most average developers, so we provided a high-level and feature rich client which is actually a wrapper around the low level raw client generated from IDL. The high level producer not only provides a simpler and intuitive interface for average application developers, but provides advanced features like partitioning, compression, asynchronous batching, further improving the message producing performance. Let’s see the main design elements of the producer below.
The Interface
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
This interface is quite self explanatory, a real IProducer implementation is here, to publish data to Luxun server, you just call send with target topic and data(or a list of data) as input, optionally, you may :
- Provide an Encoder to let the producer know how to convert your data into binary format,
- Provide an IPartitioner to let the producer know how to choose the target Luxun borker, in such case, you may also provide a partition key as part of the data.
Partitioning
At producer side, Luxun supports distribution through client side partitioning - the producer will choose a target broker using the default or user specified partitioner, if the default random partitioner is used, then the producer will pick a server at random when producing data, this end up with a distributed queue that each server stands alone and is strongly ordered, making the cluster loosely ordered. In many situations, loose ordering is sufficient. Dropping the requirement on cross communication makes it horizontally scale to infinity and beyond: no multicast, not “elections”, no coordination at all.

It’s also feasible to use a VIP between the producers and the Luxun cluster, in such case, producers only need to know the address of VIP, the VIP will be responsible for distributing traffic to different brokers.

Compression
Big data is big consumer of network bandwidth and disk storage, compression, if used appropriately, can reduce bandwidth and storage usage to an acceptable level. Most of big data like logs are text data, making compression a high priority choice when designing the collecting system.
In current implementation, Luxun supports gzip and snappy compression, enabled by producer side setting. Below is the message encoding flow at producer side:
- Use user specified or default
Encoderto convert user provided data into binary format then wrap them in a TMessageList container object, TMessageList is generated from Thrift IDL, see definition here.- Convert the TMessageList into binary format using Thrift serialization, compress the binary according to user specified codec, if no codec specified, then the binary data won’t be compressed.
- Wrap the compressed binary data with codec into another TMessagePack container object, TMessagePack is also generated from Thrift IDL, see definition here.
- Convert the TMessagePack into binary format using Thrift serialization, then send the binary to Luxun broker by calling
produceraw API.
Below is corresponding message decoding flow at consumer side:
- Get binary data from Luxun broker by calling
consumeraw API.- Convert the binary data into a TMessagePack object by using Thrift serialization.
- Extract codec and the wrapped binary data from the TMessagePack object, decompress the binary data according to the codec.
- Convert the decompressed binary data into a TMessageList object by using Thrift serialization.
- Extract data wrapped in the TMessageList object and convert them into user format by using user specified or default
Decoder.
Batch & Asynchronous Producing
The roundtrip overhead of RPC call over network has a significant impact on the system throughput and performance, as a best practice, many big data systems use batch and asynchronous producing technology at producer side for higher throughput, our testing also showed that the performance of batch producing is far better(order of magnitude differences) than the performance of producing without batch.
Figures below vividly show the inner working of synchronous and asynchronous(aka batch) producing:


First, in both sync and async producing modes, there are a couple of sync(or async) producers cached on the producer side, and there is a one to one mapping between a sync(or async) producer and a Luxun broker, at runtime, whenever there is a producing request, the producer will pick one concrete producer instance from cache by partition policy .
In sync producer mode, the sync producer will send a message to Luxun broker everytime it gets a message sending request from calling threads, and the calling thread will block before the send call return.
In asyn producer mode, messages from sending threads will be cached in an inner blocking queue first, and there is an inner sender thread which will continuously poll messages from the queue, collate and pack messages into chunk according to target topic, and send the chunk to Luxun server eventually. In async mode, message sending is actually triggered by either of following configurable conditions:
- The number of messages in the blocking queue has reached a threshhold.
- A time interval has expired.
Async producing does not block calling thread, the calling thread just fire the message then forget, so async producing has no performance impact on upper layer calling application, it’s a preferred mode for most big data collecting scenarios.
Although the throughput of sync producing does not compare with async producing, in some situations, sync producing is a preferred mode, for example, in real time event system, speed is a top priority while throughput is a secondary consideration.
The Design of the Consumer
In current implementation, Luxun provides two kinds of consumers:
A Simple Consumer
Simple consumer only supports consuming from one broker, it is just provided for demo, testing, or for user extension, following is the main interface of simple consumer:
1 2 3 | |
As the interface show, consume by index and consume by fanoutId are supported, fetchSize setting is used for batch consuming, once the consume succeeds, a list of MessageList will be returned, one MessageList is one compressed and encoded version of ProducerData produced by producer, so before you can get real data in user format, you still need to decode according to the message decode flow described in section above.
Advanced Consumer
The advanced consumer provides high-level abstraction to simplify consuming operation, it supports distributed consuming, multi-threads consuming and group consuming features. Below is main interface to create advanced consumer:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
In this interface, the message consumer is abstracted as message stream, to create message streams, you provide a map with :
- target topic as key
- number of consuming threads(or streams) as value
The concrete IStreamFactory implementation will return a list of message streams per topic, then you can delegate these message streams to different threads for concurrent consuming.
Behind the scene, concrete IStreamFactory implementation will spawn a couple of fetcher threads(one thread for one broker) that will concurrently fetch messages in target topic in Luxun servers, and put the fetched messages into a blocking queue, MessageStream abstraction is just a wrapper around the blocking queue with additional Iterable support, when upper layer threads concurrently consume on their respective streams, they are actually contenting messages in one blocking queue.

Advanced consumer has encapsulated the message decoding flow, so when you iterate on the message stream, you will get message in user format directly.
Similar to producer, consumer uses a simple and random policy for distributed consuming, the spawned fetcher threads will continuously check broker for message, if no message available in a certain broker, the corresponding thread will back off till message is available again, this can avoid frequent while fruitless server pull.
When you finish with consuming, call close on the IStreamFactory will stop the underlying fetcher threads, then wait the blocking queue to be emptied by upper consuming threads. Call close is a must to avoid message lose.
In case one consumer is not enough to keep up with the speed of producers, several consumer can form a consumer group, in such case, every consumer in the same group will use same group id(or fanout id), and every message in a topic will be consumed by one and only one consumer. This is just the consume once semantics.
If different consumers or consumer groups use different group id(or fanout id) to consume messages in same topic, then every consumer(or consumer group) can consume independently, means every message in a topic will go to every consumer(or consume group). This is just the fanout queue semantics.
Below is a figure vividly shows the consume once queue, fanout queue and group consuming semantics, in the figure:
- There is a topic called
moondistributed on four Luxun brokers.- There are two topic
moonconsuming groups, group A and group B.- In group A, there are four topic
moonconsumers.- In group B, there are six topic
moonconsumers.
Within a consumer group, a message in a topic can only be consumed by exact one consumer, for example, in consumer group A, message marked red can only be consumed by exact one consumer. Among different consumer groups, a message can be consumed by respective groups independently, for example, both group A and B will receive a separate copy of message marked green.

Although Luxun only provides two kinds of consumer interface, it does not limit user to build more advanced consuming semantics, such as consume by index, transactional consuming, etc, by extending the raw consuming interface provide by Luxun.
Management & Monitoring
Luxun is a system software, no fancy UI, management and monitoring are de factor UI of Luxun, also essential parts of Luxun architecture.
In current implementation, management functionality is limited, administrator can only delete useless topic in Luxun broker, in the future, more management functionality will be integrated as needed.
Luxun relies on JMX for system metrics monitoring, a list of monitored metrics will be listed in a separate post for operation reference.
Performance
Intensive tests show the performance of Luxun messaging system is quite good, in single sever grade machine and single topic case, the average throughput of both producing and consuming can be >> 100MBps, this is amazing given that Luxun is a persistent messaging system. See detailed performance analysis and conclusion here.
Luxun vs Apache Kafka - the Main Differences
Although Luxun borrowed many design ideas from Apache Kafka, Luxun is not a simple clone of Kafka, it has some obvious differentiating factors:
- Luxun is based on Memory Mapped file, while Kafka is based on filesystem and OS page cache, memory mapped file is a natural bridge between volatile memory and persistent disk, hence it will have better throughput, memory mapped file also has following unique features:
- Message appended by producer thread will be immediately visible to consumer threads, even producer thread hasn’t flushed the message explicitly, this makes realtime consuming possible.
- OS will ensure the message persistence even the process crashes and there is no explicit flush before the crash.
- In Java implementation, memory mapped file dose not use heap memory directly, so the GC impact is limited.
- Luxun leveraged Thrift RPC as communication layer, while Kafka built its custom NIO communication layer and messaging protocol, custom NIO layer may have better performance, while Thrift makes generating communication infrastructure and cross-language clients(producer or consumer) fairy simple, this is a typical maintainability over performance design decision.
- Luxun message consuming is index(array like) based, while Kafka message consuming is offset based, we believe index access mode can simplify design and can separate error domain better than offset.
- Luxun uses simple and random distribution mechanism for scalability, similar to Kestrel, each server handles a set of reliable, ordered message queues. When you put a cluster of these server together, with no cross communication, and pick a server at random whenever you do a
produceorconsume, you end up with a reliable, loosely ordered message queue(in many situations, loose ordering is sufficient). On the other hand, Kafka relies on Zookeeper for distributed coordination, We believe Zookeeper is still too heavy-weight for small to medium sized companies(the main targets of Luxun), and the learning curve is still steep for average developers. Of cause, Luxun has extension point left for future possible Zookeeper integration.- Luxun only supports server level partitioning - partition a topic on different servers, while Kafka supports partitioning within a topic. Our performance test show partitioning within a topic has no performance gain, at the same time, it makes design complex.
The difference above is just difference, it’s not to say that one is better than the other, Luxun and Kafka have different architectural objectives, different target user and applications.
Contributions
Luxun borrowed design ideas and adapted source from following open source projects:
- Apache Kafka, a distributed publish-subscribe messaging system using Scala as implementation language.
- Jafka, a Kafka clone using Java as implementation language.
- Java Chronicel, an ultra low latency, high throughput, persisted, messaging and event driven in memory database. using memory mapped file and index based access mode, implemented in Java.
- fqueue, fast and persistent queue based on memory mapped file and paging algorithm, implemented in Java.
- ashes-queue, FIFO queue based on memory mapped file and paging algorithm, implemented in Java.
- Kestrel, a simple, distributed message queue system implemented in Scala, supporting reliable, loosely ordered message queue.
Many thanks to the authors of these open source projects!
Next Step
- Add a sharding layer to support partition(for distribution and scalability) and replication(for reliability and performance), may leverage gizzard sharding framework or Zookeeper.
- More clients, like C#, PHP, Ruby, Python, C++.
- Big data applications, like centralized logging, tracing, metrics, realtime events system based on Luxun.