Why a Big Queue?
This is a big data era, we are always facing challenge to find insights in big data. Last time, I have worked on the architecture and design of a large scale logging, tracing, monitoring and analytics platform, the core of the platform is a log collecting system and the core of the collector is a big queue, see figure below:
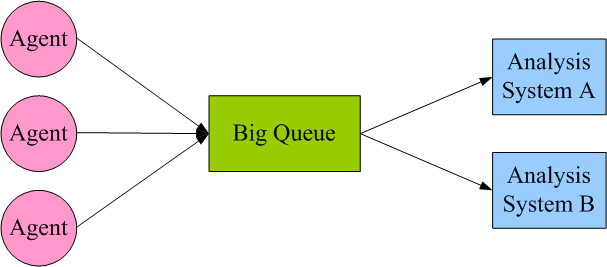
The figure above looks like a typical producing and consuming scenario, the big queue works like a broker, at the left side of the queue, there are many agents deployed on application servers, the agents work just like producers, they continuously collect log data on application servers and push them to the big queue, on the right side of the big queue, there are several analysis systems, the analysis systems work just like consumers, they continuously pull log data from the queue, analyze and store them into the backend. If you are interested in an industrial log collecting product built on this architecture, please refer to apache kafka.
Queue is a natural fit for log data collecting scenario, by leveraging queue, consumers and producers are decoupled, both sides can work without knowing the existing of other side, consumers and producers can be added or removed as needed without affecting existing ones.
The Requirements
Basically, we need the big queue to be:
- FAST & THREAD SAFE
The system needs to collect logs from more than 1000 production machines, they may produce more than 100,000 logs per second(average size is 1KB), this is equal to more than 100MB per second, if the big queue can’t keep up, logs will be lost. To further improve the throughout, we want all producers and consumers to work concurrently, so the queue needs to work in a thread safe manner, otherwise, there will be data lose or corruption. - BIG & PERSISTENT
Daily logs will be at TB level, the queue should have the capacity to store up to one week’s logs, In case any of the analysis system is down(for example, periodical maintenance or even crash), the queue should continue to store logs for backend system to consume later when they are up again. Also, if the big queue itself is down, the logs already stored should survive since they are persistent, when the queue is up again, it should continue to serve the consumers. - MEMORY EFFICIENT
Compared with big disk storage, current computer system is still shortage of physical memory, usually, memory will be less than 32GB on a commodity machine. We need the queue to use memory efficiently though it needs to handle logs more than 100MB per second and at TB level daily.
The Design Thinking Flow
Below is a simple and elegant design of the big queue I come up with to meet the requirements and challenges above:
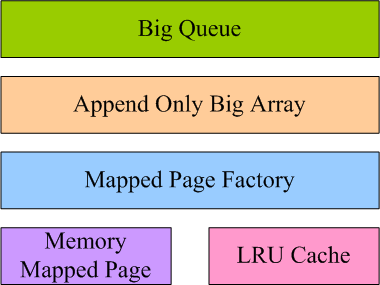
Usually, when I design something, I follow a top-down abstract thinking flow: as I learned in data structure course in college long ago, a queue data structure is usually built on an array data structure, so before I can build a queue I need to build an array first, the array I need should have following characters: first, it should be as fast as in memory access; second, it should be disk backed(hence it will be big and persistent). Seems there is contradiction between these two characters: if you need something fast, you need to put it in memory which is volatile and only has limited capacity, if you need something big and persistent, you need to put it on disk which has much slower access speed than physical memory, is there a technology to resolve these two contradictions? After an intensive research, I finally found memory mapped file which seems a natural bridge between psychical memory and disk, if you need background about memory mapped file, here and here are two good references. Now let’s continue the top-down thinking flow, before I can build a big array, I need to build a data structure called memory mapped page which can bridge the gap between speed and capacity, at the same time, I need some auxiliary structures to manage mapped pages in a memory efficient way, in the design figure above, these auxiliary structures are called mapped page factory and LRU cache. Whenever big array needs a mapped page, it requests one from the mapped page factory and returns it to the factory when it has done with the page. Mapped page factory encapsulates algorithm to allocate, cache and recycle mapped pages in a memory efficient and thread safe way by leveraging LUR cache structure.
Now, with the design in mind, I can implement these abstract structures in a bottom up, layer by layer approach, you can find the implementation details by studying the open source java code on github if you are interested.
Additional Design Notes:
Although I learned some people used to map a single big file into memory, like here and here, I have memory leak concern with such approach(though I am not sure), instead, I came with up a novel pagging and swapping algorithm which only map fixed size(for example, 128M) page file into memory on demand and unmap it when it is not accessed within a fixed time to live(TTL) period. Which such design, I can not only use memory safer and more efficient, but can delete some used pages files to save disk space whenever necessary.
As we know, queue is a rear append and front read structure, so as long as the queue front page and rear page(technically, this is called working set) are in memory, read and append operations can always happen in memory, that means the enqueue and dequeue operations are always close to O(1) memory access.
The big queue is based on a big array structure, the big array itself is an interesting data structure with some unique features(I plan to write some use cases of this structure in the near future), the big array supports sequential append(called append only array), sequential and random read. Sequential append and read are both O(1) memory access, while random read is O(1) memory access if the corresponding page is in cache, and is O(1) disk access if the corresponding page is not in cache. The big array is index based, just like normal indexed array, starting with index 0, when a new item is appended, the head index will be incremented, index is the pointer to the appended data, later you can use the index to read back the data. The index is of type long, this is a really very big range, I guess the big array won’t be used up before the world is end:).
Internally, two logical files(phycially one logical file consists of many fixed size page files) are used by one big array, one is index file, the other is data file, when data is read by index, the index will be first mapped to an index page file, then into an item in the index page file, the index item has pointer and length information to the actual data in data file, data can be retrieved by just inspecting index item, load corresponding data page file and read data in it. New data can be appended just by finding out next to be appended data page file and offset, then put the data and update corresponding index item.
Serialization is outside of the consideration of the big queue framework, the enqueue operation only accepts byte array as input(the dequeue operation only returns byte array), I left out serialization deliberately since I think it should not be the responsibility of the big queue framework, there are many existing and well known serialization frameworks(like protobuf, thrift, etc) which can do serialization work better.
To ensure thread safe, some multi-threading technologies like read-write lock and thread local buffer are leveraged, the queue can work in read/write separation way – consumer and producer can work concurrently, this tremendously improved the throughput of the queue.
The queue has interface to delete used page files(for example, if data in these page files have been consumed by consumers) to save disk space, this is called garbage collection on disk files, much like GC in memory.
Abstractly, the whole queue looks like a huge FIFO circle buffer, disk backed and memory mapped.
Performance Test
Below is the preformance test conclusion:
- In concurrent producing and consuming case, the average throughput is around 166MBps.
- In sequential producing then consuming case, the average throughput is around 333MBps.
Suppose the average message size is 1KB, then big queue can concurrently producing and consuming
166K message per second on a commodity machine under normal load. Basically, the throughput is only limited by disk IO bandwidth.
The detailed performance test report is here, the corresponding test program is here, and the full hardware spec for benchmark is here.
Conclusion
To resolve a big data challenge I designed and implemented a simple while elegant big queue that is:
- Fast : close to the speed of direct memory access, both enqueue and dequeue are close to O(1) memory access.
- Big : the total size of the queue data is only limited by the available disk space.
- Persistent : all data in the queue is persisted on disk, and is crash resistant.
- Memory-efficient : automatic paging & swapping algorithm, only most-recently accessed data is kept in memory.
- Thread-safe: multiple threads can concurrently enqueue and dequeue without data corruption.
- Simple and Light-weight: current number of source files is 12 and the library jar is less than 20K.
Log data collecting is just use case of the big queue, I can anticipate the big queue will be used in more scenarios since big data challenges are becoming common these days.