Some one did a great job to write a tutorial about the development of an end to end Android application, this is a full android application, including main activity UI, HTTP interaction, async request handling and response parsing, list view, etc. In that tutorial, the author manually parsed the response to domain objects using SAX parser built in Android, while in this post, I will show you how I adapted that application by leveraging automatic annotation driven binding supported by Nano xml binding framework.
Nano is a light-weight xml binding framework tailored for Android platform, with Nano, you can be free from error-prone and tedious xml parsing work, instead, you can focus your main development effort on application logic and UI.
The original author has elaborated the development steps of the application in his tutorial series, so in this post, I will not repeat what he has done very well, please refer to his tutorial for details about the overall application development. In this post, I will focus on the adaption of the response binding with domain objects part, using Nano binding framework.
The application is a typical movie search application, using TMDb API in the backend, if you are not familar with this API, please have a quick review of its official site, also, If you want to try the sample appliction on emulator or real Android device, you need to sign up for a TMDb account, get the API key, and replace the API key placeholder with your real key before you run the application, the source file need to be changed is this one.
Let’s cut to the chase and see how to perform the binding. The main API we will use is movie search, you can find an example response on the API usage page.
First of all, download latest Nano release by following link on this page, and put the Nano jar in the libs folder of the sample application(You can download the original application here, or you may download the whole adapted application by following link at the end of this post).
The most important thing is to create the model objects and map appropriately to the XML document by inspecting the sample response on TMDb API site. If we take a look at the XML file, we should see that the root element is called OpenSearchDescription and it includes a Query element, a “totalResults” element and a number of movies. Here is our main model class looks like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
The RootElement annotation denotes that the specific class represents a root XML element, we also provided a name parameter equals to ‘OpenSearchDescription’ in the annotation since this is the real root element name in the sample response, if this name is not provided, Nano will by default use the class name(with first chararacter in lower case) as the element name, this is not expected. We also use the Element annotations for the nested elements. Note that Nano can only handle annotations annotated directly on fields, not on get/set methods, it’s ok to annotate either public or private fields. One thing to be aware of is that we use the name parameter(for “Query” and “movies”) in order to explicitly specify the corresponding XML element name. This should be done when the XML element has a different name than the Java field, since Nano by default looks for an element with the same name as the field.
Let’s now see the Query class:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
This class contains only an attribute called “sarchTerms”, so the relevant field is annotated with Attribute.
Very easy until now. Let’s check the more complex Movie class:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
This class contains many fields, all of them map to XML element, we don’t want get trouble with writing Element annotations on every fields, so we just add a Default annotation at the class level, indicating that fields of this class should be mapped to default XML element unless explicitly specified. We also need to explicitly provide annotation parameter name on some fields(like original_name, imdb_id, last_modified_at and images) since there is a mismatch between Java field name and corresponding XML element name.
Let’s see the Image class:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
This class includes only attributes so we annotate the fields accordingly, there is no annotation on public static final fields, so these fields are not visable to Nano binding framework at runtime.
Till now, the carefull reader will find that the root MovieSearchResult class has no direct reference to the Movie class(The Movie class also has no direct reference to the Image class), the MovieSearchResult class only reference a container class called MovieContainer, why we need a container class instead of a direct Movie class reference? This is caused by a limitation of current Nano framework, it does not support inline style list yet. By inspecting the sample XML response, you will find a list of movie elements are wrapped in a movies element, but there is no specific annotation for wrapper element, so as a workaround, we build a container class for the wrapper element, below is the definition of the MovieContainer(ImageContainer is similar):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
With all domain class mapping defined, the final step is to write the response binding code, this is quite simple since the original author designed the application in a quite clean way, just find the GenericSeeker abstract class in the services package, in the class we define and initialize a Nano xml reader, see below(most irrelevant content of this class is omitted here to save space):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Then in the concrete MovieSeeker class we bind the HTTP response with MovieSearchResult class instance in Nano way, the binding can’t be simpler, it’s only one java statement, below is an extract of the MovieSeeker class:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
That’s all I have done to adapt the orignal application to use Nano binding instead, now let’s run the sample in emulator(don’t forget to fill in your API key before run), below is a screenshot:
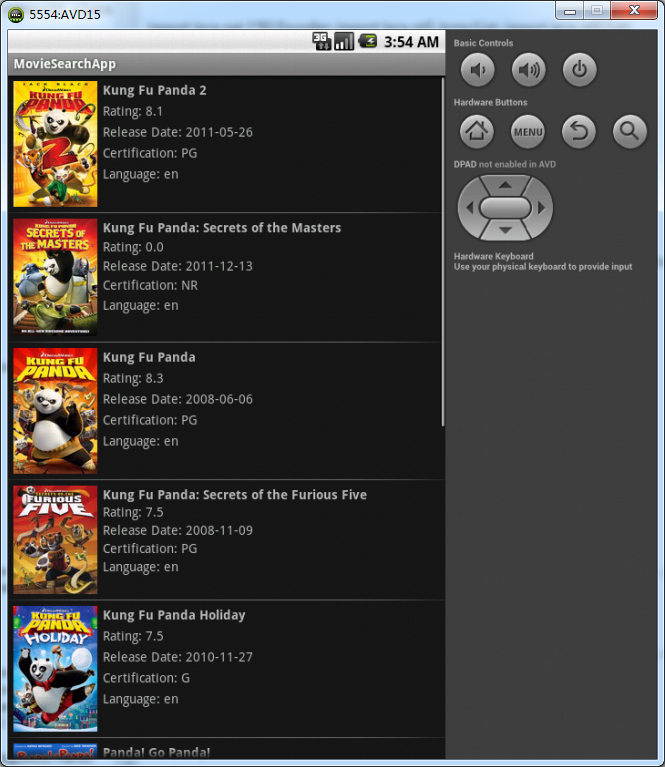
Cool! with automatic annotation driven binding supported by Nano, there is no error-prone and tedious manual xml parsing anymore, the whole application becomes even more cleaner and maintainable. So, when you develop your next xml service based Android application, remember that manual xml parsing is not necessary on Android platform, it can be completely automated by Nano binding framework!
You may get the whole source of the adapted application here.
At last, I would thank the original author again for a great tutorial he has written!